作者:燕阳阳消_469 | 来源:互联网 | 2023-07-26 18:55
篇首语:本文由编程笔记#小编为大家整理,主要介绍了flink 缓存问题处理过程,看我十八般武艺相关的知识,希望对你有一定的参考价值。
1、问题描述
作为flink小白,第一次写flink的任务,所以战战兢兢的复写了官方的demo,还好一切顺利,自信心倍增,开始进入业务需求。
但是作为一个新手不踩几个坑那说不过去,所以遇上了第一个大的门槛。
1.1 版本信息
flink版本:1.15.2
java 版本:jdk11
OS:Ubuntu 18.04
1.2 lib 包冲突的问题
第一次使用flink 哪知道flink还有个lib 目录,在使用的过程中出现了包的冲突,主要其他同学在测试的过程中瞎鸡儿搞,放了几个包在lib下,也莫名其妙,不过好在身边有人帮忙解决了问题,将maven中的flink提供的核心包设置为provided,这个很简单。
1.3 缓存问题
这个问题最初不是我遇到的,是同事遇到了,但是花了好多时间也没解决,就放弃了。我接过来处理。这里说下背景,flink我们使用的是standalone 模式,并且是另外一个同事安装的。也不知道做了什么配置,也是第一次写flink,甚至都不知道怎么提交任务,在同事手把手教的情况下上车,所以直接上手难度挺高。
开发的一个任务,提交之后,因为有问题,所以直接报错了,看下报错日志。
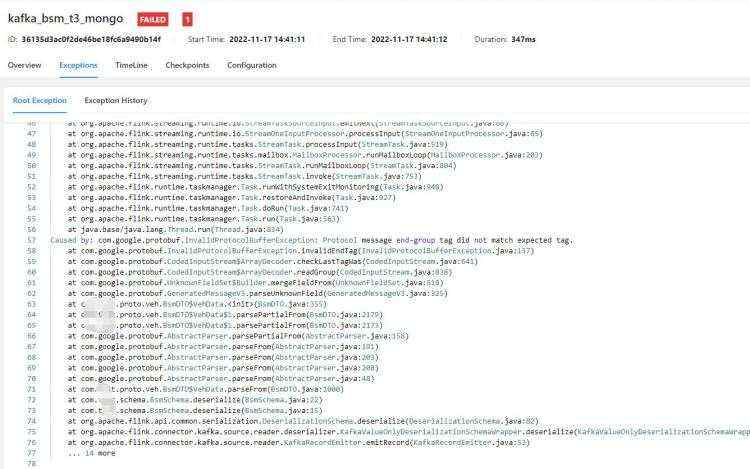
看日志还是挺明显的,proto解析失败,遇到bug解决bug,所以后面修改代码,做了异常捕获,但是不管怎么修改,每次提交都是包这个错误,真的是头秃,解决不了。
看下等会一直在说的代码,这个类主要是做kafka数据的解析,将kafka中的数据解析成VehData。
public class BsmSchema implements DeserializationSchema
@Override
public BsmDTO.VehData deserialize(byte[] bytes) throws IOException
try
if (Objects.nonNull(bytes) && bytes.length != 0)
BsmDTO.VehData bsm = BsmDTO.VehData.parseFrom(bytes);
return bsm;
catch (Exception e)
return null;
@Override
public boolean isEndOfStream(BsmDTO.VehData dpe)
return false;
@Override
public TypeInformation getProducedType()
return TypeInformation.of(new TypeHint<>()
);
2、解决过程
2.1 proto 解析失败
这个还是很简单的&#xff0c;因为数据的问题导致数据解析失败&#xff0c;所以直接通过try catch 对异常数据不处理&#xff0c;在本地测试通过后是正常的&#xff0c;打包之后&#xff0c;上传jar &#xff0c;直接上面同样的错误。无语
2.2 确认try catch
因为报了同样的错误&#xff0c;所以认为没有打包进最新的代码&#xff0c;直接反编译代码&#xff0c;确认代码中存在try catch
2.3 去除proto解析的问题
因为一直报proto解析错误&#xff0c;那我就索性去掉了proto的解析部分&#xff0c;我直接返回了一个null&#xff0c;可以看到不会再有proto解析了。
public BsmDTO.VehData deserialize(byte[] bytes) throws IOException
// try
// if (Objects.nonNull(bytes) && bytes.length !&#61; 0)
// BsmDTO.VehData bsm &#61; BsmDTO.VehData.parseFrom(bytes);
// return bsm;
//
// catch (Exception e)
//
return null;
结果就是同样的报错&#xff0c;BsmSchema 的15行&#xff0c;这就很奇怪了&#xff0c;代码里根本没这一行代码&#xff0c;当然也通过反编译确认了没有这个代码。这里基本上验证了Flink运行的根本不是我刚刚提交的最新代码。真的是奇怪啊&#xff0c;这里我也确认了缓存的存在。
2.4 其他的任务运行正常
因为报的proto解析失败&#xff0c;BsmSchema 的15行&#xff0c;刚好有一个其他任务也是使用的这个BsmSchema &#xff0c;但是其他任务运行正常&#xff0c;所以猜测不是这个类的问题。
2.5 手动清除缓存
web.tmpdir&#xff1a;/tmp/flink-web-600c749d-ca2b-4467-a557-923c955632a8
Job Manager下有这个web.tmpdir 的配置路径&#xff0c;所有上传的jar包都会存在这里。
手动清除之前上传的包&#xff0c;再次上传后&#xff0c;依然同样的报错&#xff0c;无语死了
2.6 控制台运行&#xff0c;试图越过缓存
因为之前一直使用的是web ui 提交的&#xff0c;所以怀疑是web 系统做了缓存&#xff0c;所以直接上传jar包到lib下&#xff0c;通过flink运行
flink run xxx.jar ,运行过后同样的报错&#xff0c;只不过这次展示在控制台。
最终的结果还是报错&#xff0c;报同样的错&#xff0c;有点崩溃了。
2.7 修改包名&#xff0c;试图越过缓存
猜测是缓存的问题&#xff0c;还是想越过缓存&#xff0c;猜测是jar的名字&#xff0c;所以在打包的时候直接修改了jar的名字。
还是同样的报错&#xff0c;没有一丝丝防备&#xff0c;也没有一丝丝顾虑&#xff0c;还是报错。
2.8 复刻环境&#xff0c;重现问题
实在没招了&#xff0c;只能怪环境了&#xff0c;还能咋样&#xff0c;在其他的机器上复刻一个同样版本的flink&#xff0c;然后提交任务发现执行正常&#xff0c;唉&#xff0c;还是那个环境的问题&#xff0c;这到底是为什么呐&#xff0c;难受
2.9 怀疑是包冲突导致
没有什么解决方案&#xff0c;就在这疑神疑鬼&#xff0c;怀疑是包冲突导致的&#xff0c;虽然没有一丝丝的痕迹显示如此&#xff0c;但是因为自己有限的知识&#xff0c;只能瞎猜了&#xff0c;把很多包都设置为provided的&#xff0c;打包上传&#xff0c;报错依旧没有解决。
2.10 求助大佬
寻寻觅觅&#xff0c;冷冷清清&#xff0c;凄凄惨惨戚戚&#xff0c;实在没招了&#xff0c;只能向大佬求助&#xff0c;在描述一顿问题之后&#xff0c;几个大佬都说没遇到过类似的问题&#xff0c;没办法了&#xff0c;只能自力更生。
3、解决方案
经过2天的折腾&#xff0c;实在没招了&#xff0c;也没有人求助了&#xff0c;只能自己瞎捉摸了&#xff0c;中午睡觉都在想这件事。唉&#xff0c;难受。
在下午的时候灵机一动&#xff0c;包名修改了没用&#xff0c;试着修改mainclass 的名字&#xff0c;修改之后&#xff0c;上传&#xff0c;果然解决了&#xff0c;困扰多日的问题终于解决了&#xff0c;在那一刻我被自己的聪明震惊了。哈哈&#xff0c;我可真是个机灵鬼。
4、总结
事后没有去重现这次问题&#xff0c;但是大概猜到了这个业务逻辑&#xff0c;
不知道是什么原因导致将flink 对提交的jar 做了类似缓存的操作&#xff0c;这个缓存的key 就是mainClass 的类名&#xff0c;所以换了类名之后就解决了问题
可能有人会问为什么不重启flink&#xff0c;首先原因是因为有一些任务在运行&#xff0c;重启会影响他们&#xff0c;也会破坏这个问题环境&#xff0c;
最后在解决问题的过程中也学习了一些flink其他的知识。解决问题的成就感满满


![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号